Récupérer des informations cachées d'un site web ?


Vous avez besoin d'automatiser une action sur un site web ?
Effectuer du scraping ?
Du crawling ?
Récolter des informations cachées ?
Je vais vous montrer plusieurs manières de trouver l'API REST interne d'un site web, accéder à certaines ressources privées et récolter des informations qui ne sont pas censées être rendues publiques !
Les API internes
La plupart des sites web possèdent une API REST interne afin de pouvoir afficher des informations sur le site web nécessitant d'interroger un webservice interne ou autre.
Cela peut être pour afficher la météo, le site aura par exemple besoin d'interroger un service interne stockant la météo à l'heure actuelle se trouvant à l'URL "/current-weather.json" par exemple.
Inspecteur Gadget, méthode n°1
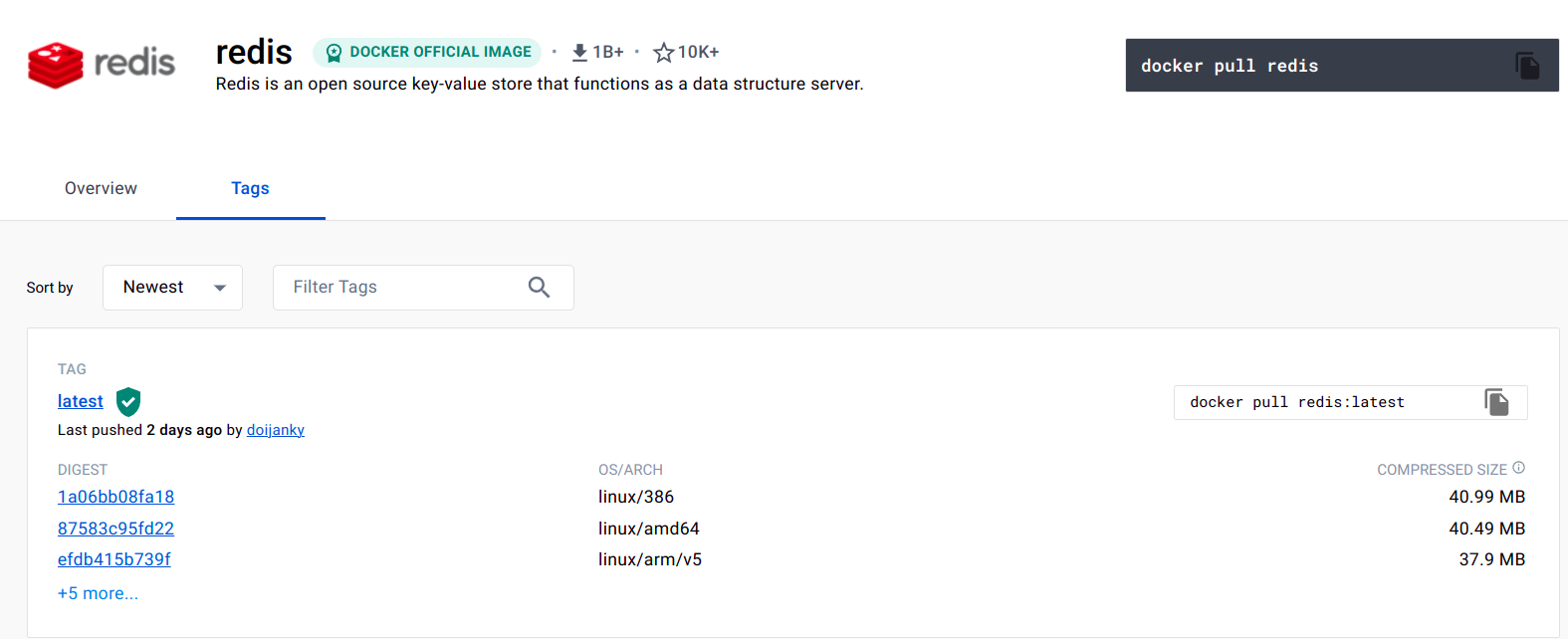
Prenons la peau d'un inspecteur avec l'exemple du Docker Hub, la registry officielle de Docker où nous récupérons la plupart de nos images.
En allant sur l'image de Redis par exemple, en ouvrant la console de développeur de mon navigateur dans l'onglet "Réseau" je peux voir certaines informations qui ne sont pas affichées sur la page !
Voici les informations de la page :
Et voici les informations en inspectant les requêtes réseau :
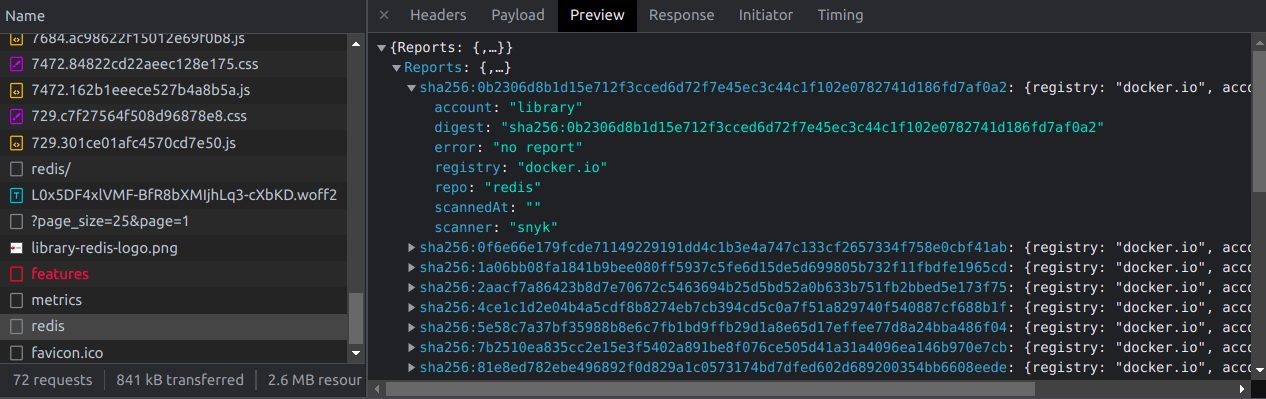
Nous pouvons donc voir l'outil qui scanne les images Docker qui est "Snyk", ce qui n'est pas affiché sur la page !
J'aurais pu prendre plein d'autres exemples ! Beaucoup de sites web exposent certaines informations dans la réponse de la requête HTTP mais ne l'affichent pas forcément sur le Frontend.
Détective privé, méthode n°2
Une méthode qui marche parfois, c'est essayer d'accéder à certains endpoints comme :
nom_de_domaine/apinom_de_domaine/api/v1api.nom_de_domaine
Essayez d'accéder à ces endpoints avec des requêtes GET et POST. Si vous avez des codes retour HTTP différents, c'est que vous êtes sur la bonne voie !
Il se peut parfois, si l'API n'est pas protégée par une authentification très forte, d'accéder à l'API de cette manière.
Gogo Gadget, méthode n°3
La méthode n°3 consiste tout simplement à afficher le code source de la page et rechercher le contenu souhaité. Cela peut paraître bête, mais beaucoup de données cachées peuvent se glisser dans le code source.
Voici un exemple ci-dessous en analysant le code source d'un repository Gitlab où le lien vers un fichier manifest.json est exposé :

Cet exemple ne montre pas l'exposition d'un fichier critique car il ne contient que certaines métadonnées, mais il est possible de tomber sur des données très critiques exposées dans le code source.
Enquêteur, méthode n°4
La méthode n°4 consiste à essayer d'accéder à certaines ressources pouvant contenir des informations intéressantes. Quelques exemples :
- Le fichiers
/robots.txt(permettant d'indiquer aux robots de Google quels page référencer et d'autres non) - Le fichier
/sitemap.xmlqui répertorie les pages du site qui doivent être indexées par les moteurs de recherche. - Les ressources Wordpress comme
/wp-contentou encore la fameuse/wp-admin
Nous verrons dans un prochain article, comment récupérer des informations cachées sur une application Android !