

Parser du XML en Python
Il peut arriver de vouloir parser du XML pour notamment les API SOAP qui utilisent ce format de données, les flux RSS ou encore pour récupérer les métadonnées des images vectorielles (format SVG). Nous allons voir dans cet article comment parser du XML en Python.
Contexte
On est jamais mieux servi que par soi-même non ? C'est sur ce dicton que je vais baser le contexte de cet article en utilisant le flux RSS de mon propre site web !
Pour rappel, un flux RSS est un format de données permettant de tenir au courant des mises à jour de contenu. Il permet de s'abonner à des sites web et de recevoir automatiquement les dernières actualités, articles, ou autres types de contenus publiés par ces sites. Ce format de données est représenté en XML, c'est pour cela que nous nous intéressons à cela.
L'URL de mon flux RSS est : https://dynops.fr/rss
On parse
Maintenant que nous avons le contexte, il est temps de passer au moment où l'on va parser ce flux RSS afin d'y récupérer certaines métadonnées. Notre premier objectif va être d'afficher le nom de mon site web.
Lorsque l'on affiche le flux RSS sur notre navigateur, ça donne ça :
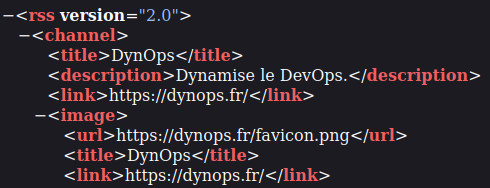
On peut voir que le nom de mon site "DynOps" se trouve dans la balise XML <title> et dépend de deux balises : <rss> et <channel>. Analysons tout cela !
Tout d'abord, pour parser du XML en Python, il faut importer le module Python lxml comme ceci :
pip install lxmlPuis importons ce qu'il y a de nécessaire dans ce module :
from lxml import etreeDans mon cas, je vais effectuer une requête HTTP GET sur mon site web. J'aurais besoin du module Python requests et je vais initialiser la variable contenant l'URL de mon flux RSS comme ceci :
from lxml import etree
import requests
rss_url = "https://dynops.fr/rss"
response = requests.get(rss_url)J'aurais besoin de récupérer le réponse HTTP sous forme de flux brut d'octets. J'utilise donc la méthode .content en ajoutant ceci à mon code :
xml_content = response.contentJusqu'ici, si la variable xml_content stocke le XML de mon flux RSS.
Le XPath
Abordons une nouvelle notion : le XPath. Il s'agit tout simplement du moyen d'identification d'une partie d'un fichier XML. Dans notre cas, l'arborescence pour le nom de mon site web correspond à ceci : /rss/channel/title.
Cela veut dire que l'on parcourt d'abord la balise rss puis channel et enfin title. Nous venons tout simplement de constituer notre XPath.
La suite serait donc d'identifier dans la partie du XML récupérée, le nom de mon site via son XPath comme ceci :
parsed_xml = etree.fromstring(xml_content)
get_title = parsed_xml.xpath("/rss/channel/title/text()")[0]
print(get_title)Le résultat nous renvoie bien "DynOps" !
Maintenant, prenons un exemple où nous allons itérer sur plusieurs éléments : le nom de chacun de mes articles.
Le XPath correspondant au nom de mes articles correspond à :
get_articles_titles = parsed_xml.xpath("/rss/channel/item/title/text()")Pour itérer dans tous ces articles, rien de plus simple qu'une boucle for comme celle-ci :
for article in get_articles_titles:
print(article)Cela vous renvoie le nom de mes articles ligne par ligne !
Voici le code Python au complet qui parse le XML de mon flux RSS et affiche le nom de mon site web :
from lxml import etree
import requests
rss_url = "https://dynops.fr/rss"
response = requests.get(rss_url)
xml_content = response.content
parsed_xml = etree.fromstring(xml_content)
get_title = parsed_xml.xpath("/rss/channel/title/text()")[0]
print(get_title)
get_articles_titles = parsed_xml.xpath("/rss/channel/item/title/text()")
for article in get_articles_titles:
print(article)Vous savez maintenant comment parser du XML en Python, il ne vous reste plus qu'à ajouter mon flux RSS en favori et le tour est joué !


